
Case study: Map two sequence sets using BLAST or FASTA34
View as Movie  BeanShell
script along with data (zipped)
BeanShell
script along with data (zipped) 
Keywords:
mapping by sequence, BLAST, FASTA, standalone [SEQs vs. SEQs using BLAST or FASTA34]
Initial situation:
You have two sequence sets you want to map. In our example we want to find the E.coli proteins that are contained in the virulence factor database.
Data:
| File | Content |
| virulence_proteins.fasta | a set of virulence factor proteins, multi FASTA file |
| Escherichia_coli_O157_H7_EDL933.fasta | E.coli sequences, multi FASTA file |
Steps
Step 1: Data import 2x
For loading the multi FASTA files into PROMPT, choose
“Import -> FASTA -> File”
and choose “protein” as sequence type in the following dialog.
After you have loaded both FASTA files, your workspace may look now similar like this:
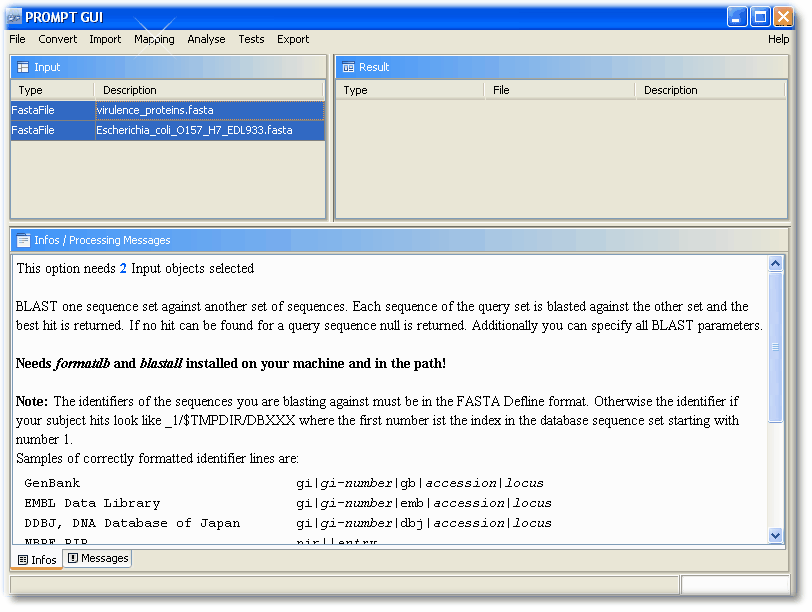
Step 2: Mapping & Results
Select both files in the input view and choose from the menu:
"Mapping -> BLAST one seq. set against another"
alternatively you can use the FASTA34 algorithm with the menu command
"Mapping -> FASTA one seq. set against another"
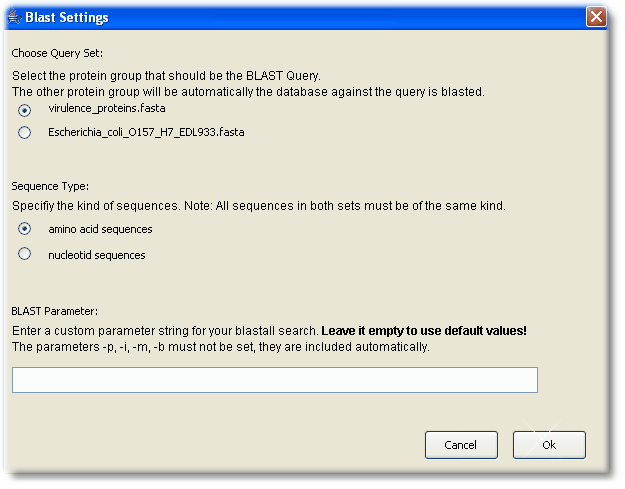
In the mapping dialog, check the radio button next to "virulence_proteins.fasta" to select the protein set that should be the query. As sequence type, check amino acid sequences and click "OK"
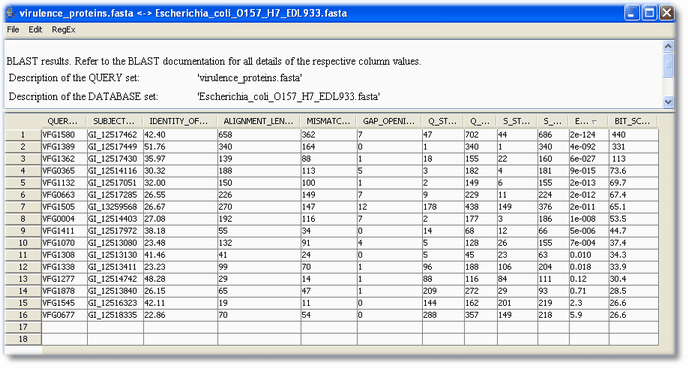
Switch to the message tab to see processing messages. After all sequences have been processed, a new result will show up in the result section.
Summary:
- Map any identifier sets with sequences. The next case study shows the mapping if only protein identifier are available.
- Mapping can be done with BLAST or FASTA34.
More:
Start PROMPT, Download PROMPT or sign up to the Community Mailing List
| Previous case study: Fast-Mapping against a large remote database like UniProt-Trembl |
Back to the Case studies Overview |
Next case study: Map a list of GenBank identifiers to a list of Swiss-Prot accessions |